Most CANSIM data can be accessed in two formats: as data tables and, at a much more granular level, as individual data vectors. This post is structured accordingly:
Table of Contents
Searching for Data
CANSIM data is stored in tables containing data on a specific subject. Individual entries (rows) and groups of entries in these tables are usually assigned vector codes. Thus, unless we already know what table or vector we need, finding the correct table should be our first step.
As always, start with loading packages:
Now we can start retrieving CANSIM data. How we do this, depends on whether we already know the table or vector numbers. If we do, things are simple: just use get_cansim() to retrieve data tables, or get_cansim_vector() to retrieve vectors.
But usually we don’t. In this case one option is to use StatCan’s online search tool. Eventually you will find what you’ve been looking for, although you might also miss a few things – CANSIM is not that easy to search and work with manually.
A much better option is to let R do the tedious work for you with a few lines of code.
Searching by Index
In this example (based on the code I wrote for a research project), let’s look for CANSIM tables that refer to Aboriginal (Indigenous) Canadians anywhere in the tables’ titles, descriptions, keywords, notes, etc.:
# create an index to subset list_cansim_tables() output
index <- list_cansim_tables() %>%
Map(grepl, "(?i)aboriginal|(?i)indigenous", .) %>%
Reduce("|", .) %>%
which()
# list all tables with Aboriginal data, drop redundant cols
tables <- list_cansim_tables()[index, ] %>%
select(c("title", "keywords", "notes", "subject",
"date_published", "time_period_coverage_start",
"time_period_coverage_end", "url_en",
"cansim_table_number"))
Let’s look in detail at what this code does. First, we call the list_cansim_tables() function, which returns a tibble dataframe, where each row provides a description of one CANSIM table. To get a better idea of list_cansim_tables() output, run:
glimpse(list_cansim_tables())
Then we search through the dataframe for Regex patterns matching our keywords. Note the (?i) flag – it tells Regex to ignore case when searching for patterns; alternatively, you can pass ignore.case = TRUE argument to grepl(). The Map() function allows to search for patterns in every column of the dataframe returned by list_cansim_tables(). This step returns a very long list of logical values.
Our next step is to Reduce() the list to a logical vector, where each value is either FALSE if there was not a single search term match per CANSIM table description (i.e. per row of list_cansim_tables output), or TRUE if there were one or more matches. The which() function gives us the numeric indices of TRUE elements in the vector.
Finally, we subset the list_cansim_tables() output by index. Since there are many redundant columns in the resulting dataframe, we select only the ones that contain potentially useful information.
Searching with dplyr::filter
There is also a simpler approach, which immediately returns a dataframe of tables:
tables <- list_cansim_tables() %>%
filter(grepl("(?i)aboriginal|(?i)indigenous", title)) %>%
select(c("title", "keywords", "notes", "subject",
"date_published", "time_period_coverage_start",
"time_period_coverage_end", "url_en",
"cansim_table_number"))
However, keep in mind that this code would search only through the column or columns of the list_cansim_tables() output, which were specified inside the grepl() call (in this case, in the title column). This results in fewer tables listed in tables: 60 vs 73 you get if you search by index (as of the time of writing this). Often simple filtering would be sufficient, but if you want to be extra certain you haven’t missed anything, search by index as shown above.
( ! ) Note that some CANSIM data tables do not get updated after the initial release, so always check the date_published and time_period_coverage_* attributes of the tables you are working with.
Saving Search Results
Finally, it could be a good idea to externally save the dataframe with the descriptions of CANSIM data tables in order to be able to view it as a spreadsheet. Before saving, let’s re-arrange the columns in a more logical order for viewers’ convenience, and sort the dataframe by CANSIM table number.
# re-arrange columns for viewing convenience
tables <- tables[c("cansim_table_number", "title", "subject",
"keywords", "notes", "date_published",
"time_period_coverage_start",
"time_period_coverage_end", "url_en")] %>%
arrange(cansim_table_number)
# and save externally
write_delim(tables, "selected_data_tables.txt", delim = "|")
( ! ) Note that I am using write_delim() function instead of a standard write.csv() or tidyverse::write_csv(), with | as a delimiter. I am doing this because there are many commas inside strings in CANSIM data, and saving as a comma-separated file would cause incorrect breaking down into columns.
Now, finding the data tables can be as simple as looking through the tables dataframe or through the selected_data_tables.txt file.
Retrieving Data Tables
In order for the examples here to feel relevant and practical, let’s suppose we were asked to compare and visualize the weekly wages of Aboriginal and Non-Aboriginal Canadians of 25 years and older, living in a specific province (let’s say, Saskatchewan), adjusted for inflation.
Since we have already searched for all CANSIM tables that contain data about Aboriginal Canadians, we can easily figure out that we need CANSIM table #14-10-0370. Let’s retrieve it:
wages_0370 <- get_cansim("14-10-0370")
Note that a few CANSIM tables are too large to be downloaded and processed in R as a single dataset. However, below I’ll show you a simple way how you can work with them.
Cleaning Data Tables
CANSIM tables have a lot of redundant data, so let’s quickly examine the dataset to decide which variables can be safely dropped in order to make working with the dataset more convenient:
names(wages_0370)
glimpse(wages_0370)
( ! ) Before we proceed further, take a look at the VECTOR variable – this is how we can find out individual vector codes for specific CANSIM data. More on that below.
Let’s now subset the data by province, drop redundant variables, and rename the remaining in a way that makes them easier to process in the R language. Generally, I suggest following The tidyverse Style Guide by Hadley Wickham. For instance, variable names should use only lowercase letters, numbers, and underscores instead of spaces:
wages_0370 <- wages_0370 %>%
filter(GEO == "Saskatchewan") %>%
select(-c(2, 3, 7:12, 14:24)) %>%
setNames(c("year", "group", "type", "age", "current_dollars"))
Next, let’s explore the dataset again. Specifically, let’s see what unique values categorical variables year, group, type, age have. No need to do this with current_dollars, as all or most of its values would inevitably be unique due to it being a continuous variable.
map(wages_0370[1:4], unique)
The output looks as follows:
#> $ year [1] “2007” “2008” “2009” “2010” “2011” “2012” “2013” “2014” “2015” “2016” “2017” “2018”
#> $ group [1] “Total population” “Aboriginal population” “First Nations” “Métis” “Non-Aboriginal population”
#> $ type [1] “Total employees” “Average hourly wage rate” “Average weekly wage rate” “Average usual weekly hours”
#> $ age [1] “15 years and over” “15 to 64 years” “15 to 24 years” “25 years and over” “25 to 54 years”
Now we can decide how to further subset the data.
We obviously need data for as many years as we can get, so we keep all the years from the year variable.
For the group variable, we need Aboriginal and Non-Aboriginal data, but the “Aboriginal” category has two sub-categories: “First Nations” and “Métis”. It is our judgment call which to go with. Let’s say we want our data to be more granular and choose “First Nations”, “Métis”, and “Non-Aboriginal population”.
As far as the type variable is concerned, things are simple: we are only interested in the weekly wages, i.e. “Average weekly wage rate”. Note that we are using the data on average wages because for some reason CANSIM doesn’t provide the data on median wages for Aboriginal Canadians. Using average wages is not a commonly accepted way of analyzing wages, as it allows a small number of people with very high-paying jobs to distort the data, making wages look higher than they actually are. This happens because the mean is highly sensitive to large outliers, while the median is not. But well, one can only work with the data one has.
Finally, we need only one age group: “25 years and over”.
Having made these decisions, we can subset the data. We also drop two categorical variables (type and age) we no longer need, as both these variables would now have only one level each:
wages_0370 <- wages_0370 %>%
filter(grepl("25 years", age) &
grepl("First Nations|Métis|Non-Aboriginal", group) &
grepl("weekly wage", type)) %>%
select(-c("type", "age"))
Using Pipe to Stitch Code Together
What I just did step-by-step for demonstration purposes, can be done with a single block of code to minimize typing and remove unnecessary repetition. The “pipe” operator %>% makes this super-easy. In R-Studio, you can use Shift+Ctrl+M shortcut to insert %>%:
wages_0370 <- get_cansim("14-10-0370") %>%
filter(GEO == "Saskatchewan") %>%
select(-c(2, 3, 7:12, 14:24)) %>%
setNames(c("year", "group", "type",
"age", "current_dollars")) %>%
filter(grepl("25 years", age) &
grepl("First Nations|Métis|Non-Aboriginal", group) &
grepl("weekly wage", type)) %>%
select(-c("type", "age"))
Retrieving Data Vectors
How to Find the Right Vector
Now that we have our weekly wages data, let’s adjust the wages for inflation, otherwise the data simply won’t be meaningful. In order to be able to do this, we need to get the information about the annual changes in the Consumer Price Index (CPI) in Canada, since the annual change in CPI is used as a measure of inflation. Let’s take a look at what CANSIM has on the subject:
# list tables with CPI data, exclude the US
cpi_tables <- list_cansim_tables() %>%
filter(grepl("Consumer Price Index", title) &
!grepl("United States", title))
Even when we search using filter() instead of indexing, and remove the U.S. data from search results, we still get a list of 20 CANSIM tables with multiple vectors in each. How do we choose the correct data vector? There are two main ways we can approach this.
First, we can use other sources to find out exactly which vectors to use. For example, we can take a look at how the Bank of Canada calculates inflation. According to the Bank of Canada’s “Inflation Calculator” web page, they use CANSIM vector v41690973 (Monthly CPI Indexes for Canada) to calculate inflation rates. So we can go ahead and retrieve this vector:
# retrieve vector data
cpi_monthly <- get_cansim_vector("v41690973",
start_time = "2007-01-01",
end_time = "2018-12-31")
Since the data in the wages_0370 dataset covers the period from 2007 till 2018, we retrieve CPI data for the same period. The function takes two main arguments: vectors – the list of vector numbers (as strings), and start_time – starting date as a string in YYYY-MM-DD format. Since we don’t need data past 2018, we also add an optional end_time argument. Let’s take a look at the result of our get_cansim_vector() call:
glimpse(cpi_monthly)
The resulting dataset contains monthly CPI indexes (take a look at the REF_DATE variable). However, our wages_0370 dataset only has the annual data on wages. What shall we do?
Well, one option could be to calculate annual CPI averages ourselves:
# calculate mean annual CPI values
cpi_annual <- cpi_monthly %>%
mutate(year = str_remove(REF_DATE, "-.*-01")) %>%
group_by(year) %>%
transmute(cpi = round(mean(VALUE), 2)) %>%
unique()
Alternatively, we could look through CANSIM tables to find annual CPI values that have already been calculated by Statistics Canada.
Thus, the second way to find which vectors to use, is by looking through the relevant CANSIM tables. This might be more labor-intensive, but can lead to more precise results. Also, we can do this if we can’t find vector numbers from other sources.
Let’s look at cpi_tables. Table # 18-10-0005 has “Consumer Price Index, annual average” in its title, so this is probably what we need.
# get CANSIM table with annual CPI values
cpi_annual_table <- get_cansim("18-10-0005")
Let’s now explore the data:
# explore the data
map(cpi_annual_table[1:4], unique)
# unique(cpi_annual_table$VECTOR)
Turns out, the data is much more detailed than in the vector v41690973. Remember that in wages_0370 we selected the data for a specific province (Saskatchewan)? Well, table # 18-10-0005 has CPI breakdown by province and even by specific groups of products. This is just what we need! However, if you run unique(cpi_annual_table$VECTOR), you’ll see that table # 18-10-0005 includes data from over 2000 different vectors – it is a large dataset. So, how do we choose the right vector? By narrowing down the search:
# find out vector number from CANSIM table
cpi_annual_table %>%
rename(product = "Products and product groups") %>%
filter(GEO == "Saskatchewan" &
product == "All-items") %>%
select(VECTOR) %>%
unique() %>%
print()
This gives us CANSIM vector number for the “all items” group CPI for the province of Saskatchewan: v41694489.
Using StatCan Data Search Tool to Find Vectors
Some CANSIM tables are too large to be retrieved using cansim package. For example, running get_cansim(“12-10-0136”) will result in a long wait followed by “Problem downloading data, multiple timeouts” error. cansim will also advise you to “check your network connection”, but network connection is not the problem, it is the size of the dataset.
CANSIM table 12-10-0136 is very large: 16.2 GB. By default, R loads the full dataset into RAM, which can make things painfully slow when dealing with huge datasets. There are solutions for datasets <10 GB in size, but anything larger than 10 GB requires either distributed computing, or retrieving data chunk-by-chunk. In practice, in R you are likely to start experiencing difficulties and slowdowns if your datasets exceed 1 GB.
Suppose we need to know how much wheat (in dollars) Canada exports to all other countries. CANSIM table 12-10-0136 “Canadian international merchandise trade by industry for all countries” has this data. But how do we get the data from this table if we can’t directly read it into R, and even if we manually download and unzip the dataset, R won’t be able to handle 16.2 GB of data?
This is where CANSIM data vectors come to the rescue. We need to get only one vector instead of the whole enormous table. To do that, we need to know the vector’s number, but we can’t look for it inside the table because the table is too large.
The solution is to find the correct vector using Statistics Canada Data search tool. Start with entering the table number in the “Keyword(s)” field. Obviously, you can search by keywords too, but searching by table number is more precise:
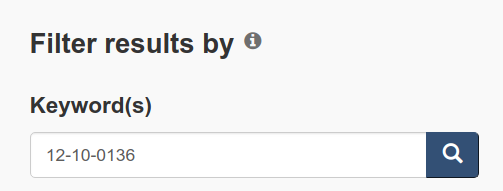
Then click on the name of the table: “Canadian international merchandise trade by industry for all countries”. After the table preview opens, click “Add/Remove data”:
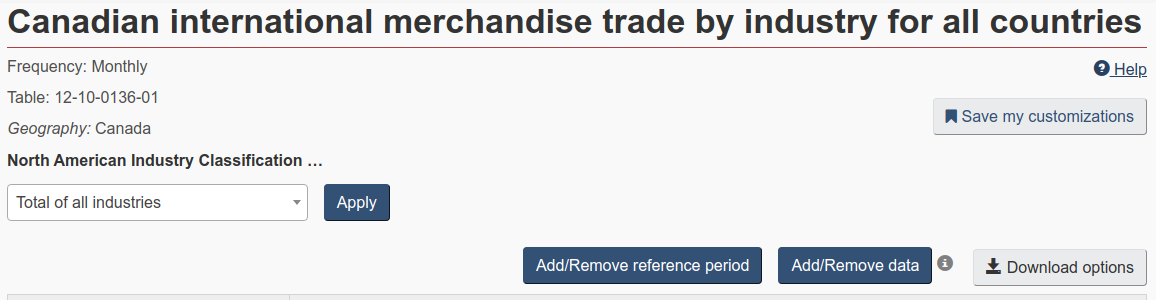
The “Customize table (Add/Remove data)” menu will open. It has the following tabs: “Geography”, “Trade”, “Trading Partners”, “North American Industry Classification System (NAICS)”, “Reference Period”, and “Customize Layout”. Note that the selection of tabs depends on the data in the table.
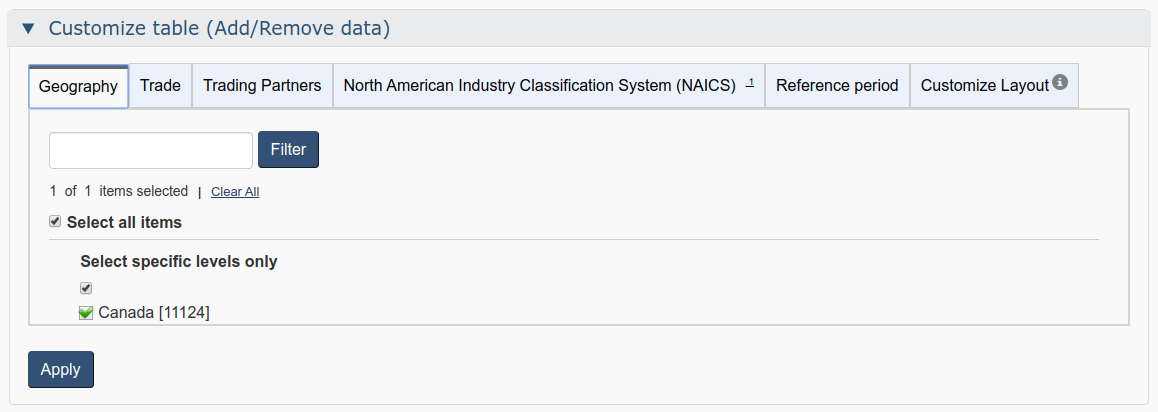
Now, do the following:
In the “Geography” tab, do nothing – just make sure “Canada” is checked.
- In the “Trade” tab, uncheck “Imports”, since we are looking for the exports data.
- In the “Trading Partners”, check “Total of all countries” and uncheck everything else.
- Skip “Reference period” for now.
- In “Customize Layout”, check “Display Vector Identifier and Coordinate”.
- Finally, in the “North American Industry Classification System (NAICS)” tab, uncheck “Total of all industries”, find our product of interest – wheat – and check it. Then click “Apply”.
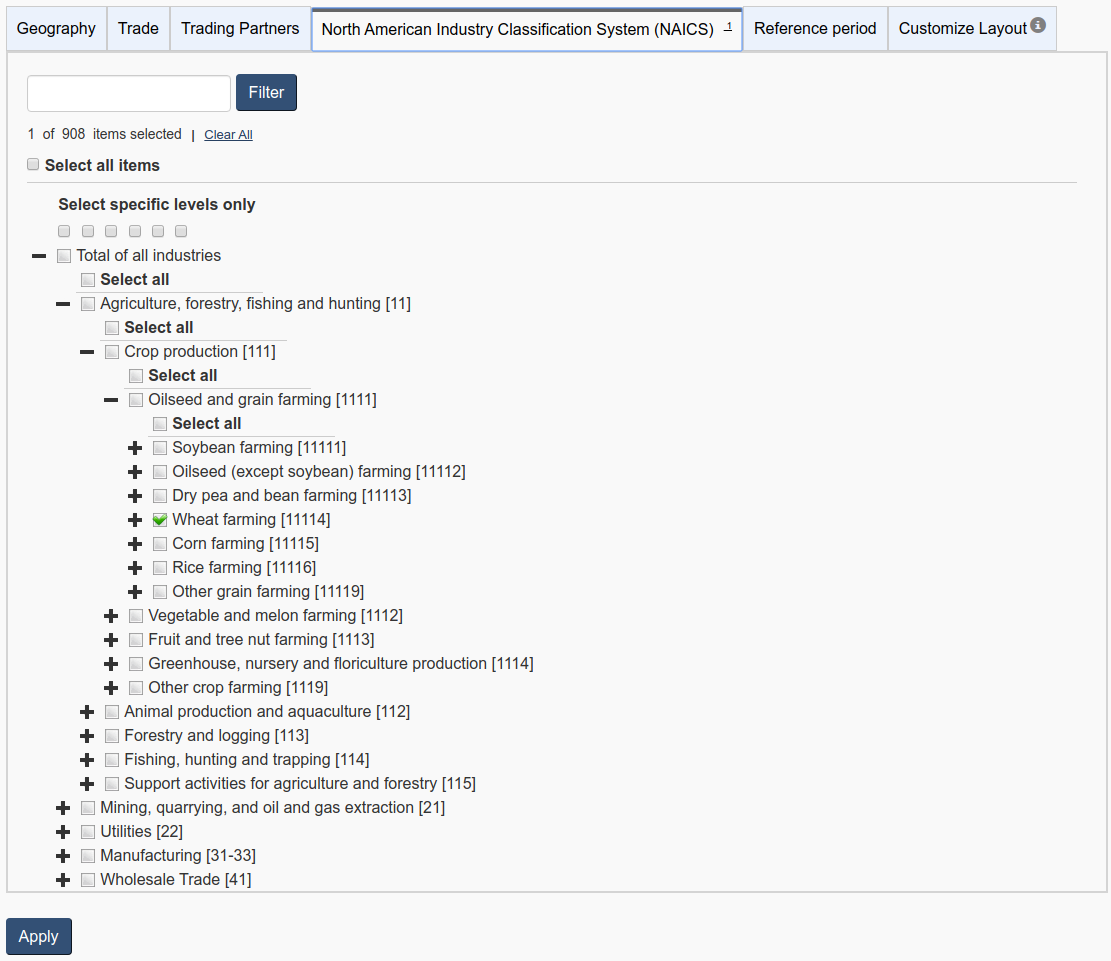
If you followed all the steps, here’s what your output should look like:
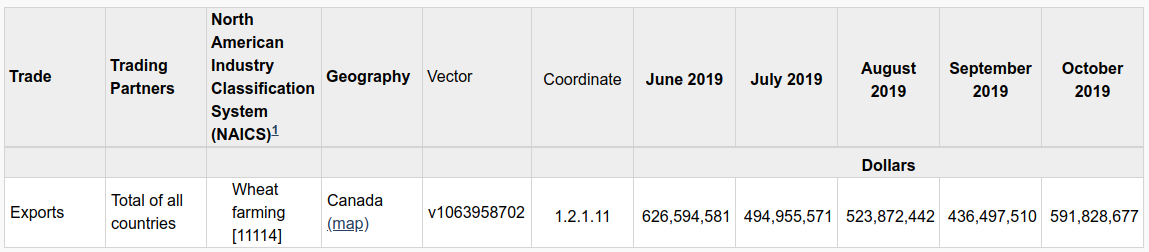
The vector number for Canada’s wheat exports to all other countries is v1063958702.
Did you notice that the output on screen has data only for a few months in 2019? This is just a sample of what our vector has. If you click “Reference period”, you’ll see that the table 12-10-0136 has data for the period from January 2002 to October 2019:
Now we can retrieve the data we’ve been looking for:
# get and clean wheat exports data
wheat_exports <-
get_cansim_vector("v1063958702", "2002-01-01", "2019-10-31") %>%
mutate(ref_date = lubridate::ymd(REF_DATE)) %>%
rename(dollars = VALUE) %>%
select(-c(1, 3:9))
# check object size
object.size(wheat_exports)
The resulting wheat_exports object is only 4640 bytes in size: about 3,500,000 times smaller than the table it came from!
Note that I used lubridate::ymd() function inside the mutate() call. This is not strictly required, but wheat_exports contains a time series, so it makes sense to convert the reference date column to an object of class “Date”. Since lubridate is not loaded with tidyverse (it is part of the tidyverse ecosystem, but only core components are loaded by default), I had to call the ymd() function with lubridate::.
Finally, note that StatCan Data has another search tool that allows you to search by vector numbers. Unlike the data tables search tool, the vector search tool is very simple, so I’ll not be covering it in detail. You can find it here.
Cleaning Vector Data
Let’s now get provincial annual CPI data and clean it up a bit, removing all the redundant stuff and changing the VALUE variable name to something in line with The tidyverse Style Guide:
# get mean annual CPI for Saskatchewan, clean up data
cpi_sk <-
get_cansim_vector("v41694489", "2007-01-01", "2018-12-31") %>%
mutate(year = str_remove(REF_DATE, "-01-01")) %>%
rename(cpi = VALUE) %>%
select(-c(1, 3:9))
As usual, you can directly feed the output of one code block into another with the %>% (“pipe”) operator:
# feed the vector number directly into get_cansim_vector()
cpi_sk <- cpi_annual_table %>%
rename(product = "Products and product groups") %>%
filter(GEO == "Saskatchewan" &
product == "All-items") %>%
select(VECTOR) %>%
unique() %>%
as.character() %>%
get_cansim_vector(., "2007-01-01", "2018-12-31") %>%
mutate(year = str_remove(REF_DATE, "-01-01")) %>%
rename(cpi = VALUE) %>%
select(-c(1, 3:9))
How to Find a Table if All You Know is a Vector
By this point you may be wondering if there is an inverse operation, i.e. if we can find CANSIM table number if all we know is a vector number? We sure can! This is what get_cansim_vector_info() function is for. And we can retrieve the table, too:
# find out CANSIM table number if you know a vector number
get_cansim_vector_info("v41690973")$table
# get table if you know a vector number
cpi_table <- get_cansim_vector_info("v41690973")$table %>%
get_cansim()
Joining Data (and Adjusting for Inflation)
Now that we have both weekly wages data (wages_0370) and CPI data (cpi_sk), we can calculate the inflation rate and adjust the wages for inflation. The formula for calculating the inflation rate for the period from the base year to year X is: (CPI in year X – CPI in base year) / CPI in base year.
If we wanted the inflation rate to be expressed as a percentage, we would have multiplied the result by 100, but here it is more convenient to have inflation expressed as a proportion:
# calculate the inflation rate
cpi_sk$infrate <- (cpi_sk$cpi - cpi_sk$cpi[1]) / cpi_sk$cpi[1]
Now join the resulting dataset to wages_0370 with dplyr::left_join(). Then use the inflation rates data to adjust wages for inflation with the following formula: base year $ = current year $ / (1 + inflation rate):
# join inflation rate data to wages_0370; adjust wages for inflation
wages_0370 <- wages_0370 %>%
left_join(cpi_sk, by = "year") %>%
mutate(dollars_2007 = round(current_dollars / (1 + infrate), 2))
We are now ready to move on to the next article in this series and plot the resulting data.